Answering technical questions about products is a key activity for businesses to deliver excellent customer service and user experience. Businesses invest considerable resources in creating high-quality product documentation, knowledge bases, FAQs, technical blogs, and other documents so that users can search for the answers to their questions. However, the current search tools available in the enterprise are primitive and leave much to be desired. Neural search is a radical new approach for tackling the enterprise search problem.
Current search tools use bag-of-words search methods that match terms from users’ queries to documents using techniques such as tf-idf and BM25. In response to the query Why is my SQL query running slow on AWS?, a bag-of-words approach finds documents that contain terms from the query, such as SQL, query, running, slow, and AWS. It ignores the word order, and the syntax of the question, and gives incorrect or irrelevant answers such as the ones below:

Term-based search fails above because it cannot capture the semantic meaning of the words, and finds irrelevant documents such as How to run SQL queries or SQL with Apache Spark (Figure 1). Furthermore, if the user does not know the precise keywords that the answer contains, then finding the correct document via term-based search becomes almost impossible.
An approach that can understand the meaning of the question and uncover deep semantic connections between the question and the documents is required to address these limitations. The phrase slow SQL queries on AWS can be expressed in a variety of different ways in documents with a similar or related meaning, e.g., i. SQL high latency query on AWS, ii. SQL performance troubleshooting on AWS EC2, or iii. High performance queries with SQL.
Documents on these topics are more likely to contain the answer than those identified by bag-of-words, but limitations of term-based search fail to identify these. SparrowLabs uses Neural Search to address this problem. Using state-of-the-art natural language understanding and machine learning techniques, neural search identifies the semantic meaning of a question and its relationship to documents.
Fine-tuned deep language models and transformers have advanced state-of-the-art for many language tasks, including document ranking. Nevertheless, ranking models based on these are limited by their slow speed and lack of domain knowledge. To compute a relevance score for a question, these models require feeding every query–document pair through a massive neural network. This significantly increases the computational cost and runtime. Even using an Nvidia V100 GPU, matching a question to a corpus of 5000 documents can take up to 40 seconds! Without domain knowledge of system-related terms, concepts, and their relationships, it is hard to understand technical questions.
Transformers trained over hundreds of gigabytes of English-language corpora are fine-tuned for the task of generating vectorized representations of text and domain specialized using data augmentation. Each document and the query is represented as a vector and these abstract numerical representations help find deep semantic connections between questions and documents. The relevance score of a document for a question is computed from the vectorized representation of the document and that of the question (Figure 2).
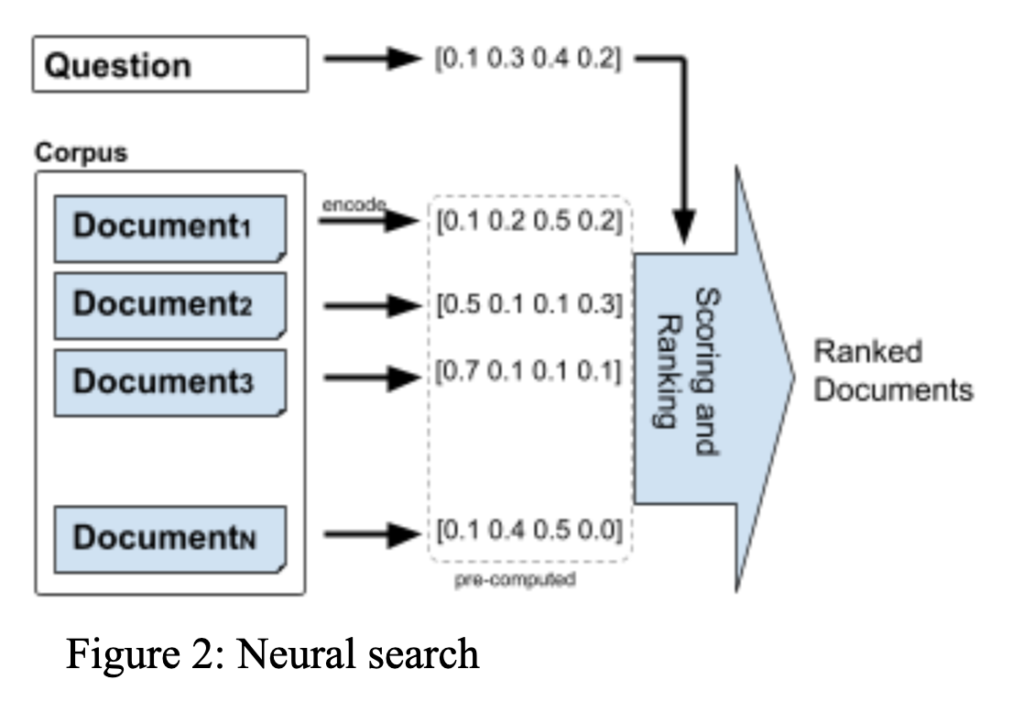
Vectorized representations of documents are pre-computed offline, which speeds up query processing by several orders of magnitude, and identifies relevant documents for answering the question in real-time:

Moreover, neural search provides the source of the answers. Based on the the document sources containing the answer, the user can judge the trustworthiness and reliability of the answer.
SparrowLabs is transforming technical product support experience with neural search, and we are excited to see the enormous benefits it brings to our customers.
